TL;DR
- Kubernetes is great at running workloads, but it doesn’t actually understand what those workloads are or why they matter.
- Modern systems are constantly buzzing with billions of signals every day—far more than any person or dashboard could possibly keep up with.
- Think of the Intelligence Layer as giving your infrastructure a memory, a sense of context, and the ability to make predictions.
- This means the team can finally get ahead of problems—catching issues before they become outages, making deployments less risky, and even fixing things automatically when something starts to go wrong.
A Familiar Nightmare
Imagine yourself as an SRE at a rapidly growing startup. Everything seems calm—dashboards are green, and alerts aren’t making a sound. But out of nowhere, your core services start to fail.
You check the basics: all the pods look healthy. Still, traffic is falling, latency is spiking, and your users are starting to notice.
The engineering team leaps into action, frantically flipping through logs, traces, and dashboards. It takes a stressful thirty minutes before you finally spot what happened: a tiny latency spike downstream quietly snowballed into a major issue that rippled across the whole system.
If this feels familiar, you’re not alone. This scenario is becoming more common every year.The Operations Complexity Crisis
Kubernetes has become the backbone of modern infrastructure. But as organizations scale, a painful reality emerges:
Kubernetes can run your applications, but it cannot understand them.Microservices Have Outgrown Human Comprehension
Today’s cloud-native organizations run hundreds of microservices across multiple clusters, with thousands of changes shipping daily and millions of pods cycling every 24 hours.
Expecting any engineer to maintain a complete mental model of such a system is unrealistic. Yet during outages, that’s exactly what teams attempt—reconstructing behavior across dozens of services by jumping between tools.
Failures Are No Longer Simple Events
In older systems, failures were straightforward: CPU hit 100%, a node went down, a service crashed. You saw the problem, you fixed it.
Today, failures emerge as chains of small signals: a database slowdown triggers retries, retries cause CPU spikes, spikes lead to throttling, throttling increases latency, and latency backs up queues. None of these signals alone looks catastrophic—but together, they tip the system over.
Telemetry Has Outpaced the Human Brain
Even medium-sized Kubernetes environments generate millions of time-series metrics every few seconds, terabytes of logs daily, and thousands of traces per second.
Here’s the uncomfortable truth: research published in Neuron (January 2025) by Caltech scientists found that humans process conscious thought at approximately 10 bits per second. Meanwhile, our sensory systems gather data at roughly 1 billion bits per second—a ratio of 100 million to 1.
There’s simply no way to manually correlate every signal into a coherent explanation—especially during an incident.
Dashboards tell you what changed. Alerts tell you something is wrong. Neither tells you why it happened or what will happen next.What Kubernetes Was Built For—and Where It Stops
Kubernetes excels at deterministic tasks: scheduling, reconciling desired state, restarting containers, and autoscaling based on threshold signals. These mechanics form the foundation of modern infrastructure.
But its design intentionally does not extend into higher-order intelligence:
- Kubernetes doesn’t predict when resources will be exhausted—it reacts after they are
- Kubernetes doesn’t understand service dependencies—it treats every pod the same
- Kubernetes doesn’t learn from past incidents—it has no memory of what happened yesterday
- Kubernetes doesn’t reason about cascading failures—it sees individual pod failures, not system-level patterns
The Missing Component: An Intelligence Layer
To understand the gap, consider the human body.
Kubernetes as the Autonomic Nervous System
Your autonomic nervous system quietly handles all the basics—your heartbeat, your breathing, your reflexes, and keeping your body temperature just right. It does these things lightning-fast and reliably, but it doesn’t really “know” what’s happening around you or why.
Kubernetes works in a similar way. It keeps your cluster’s vital signs in check: ensuring pods are running, placing them on the right nodes, restarting unhealthy components, and scaling up or down as needed. It’s fantastic at handling the nuts and bolts, but it doesn’t truly understand the bigger picture.
The Brain: What Kubernetes Never Had
The brain does something fundamentally different: it remembers, learns, reasons, predicts, and makes context-aware decisions. These are higher-order cognitive functions—and Kubernetes has none of them.
Not because Kubernetes is flawed, but because it was designed as a declarative, reactive orchestrator—not an intelligent reasoning system.
What the Intelligence Layer Adds
Memory: The Intelligence Layer sees seasonality, past failures, normal vs. abnormal traffic waves, and deployment-time characteristics. Without historical memory, there is no prediction—and without prediction, there is no prevention.
Context: Services don’t fail in isolation. They interact with databases, caches, downstream APIs, and shared resources. The Intelligence Layer learns these relationships and understands who depends on whom.
Understanding: Instead of thresholds, the system recognizes abnormal latency shapes, retry storms forming, cross-service correlation, and broken deployment patterns.
Prediction: With memory, context, and behavioral understanding, the system forecasts SLO breaches, saturation trends, and cascading failures—before users feel the impact.
Explanation: During incidents, instead of engineers spending 30 minutes gathering clues, the system presents reasoning: what changed, which dependency triggered the slowdown, and whether this matches a past incident pattern.
Real-World Impact
What does this enable for a high-scale Kubernetes environment?
Service DNA
Over time, every microservice develops its own personality—how it handles traffic, its typical response times, the kinds of errors it tends to experience, how much it consumes resources, and which other services it relies on. This unique “DNA” becomes a picture of what’s normal for each service.
Kubernetes treats all services the same. The Intelligence Layer does not.Predictive SLO Management
Alerts fire after something goes wrong. Prediction lets you act before.
With early signal detection, you can get a heads-up 15 to 20 minutes before trouble actually strikes—enough time to act, not just react. Machine learning helps cut down on false alarms, so you’re not chasing ghosts. Teams that have adopted advanced AIOps are already seeing these improvements play out in the real world, based on what’s actually happened during major incidents.
Error Budget Governance
Traditional deployment gates are binary: tests pass or fail. But “tests passed” doesn’t mean “safe to deploy.” A service already burning through its error budget shouldn’t ship new changes—regardless of test results.
The Intelligence Layer tracks error budget consumption in real-time. When your service has consumed 80% of its monthly budget, and its burn rate exceeds sustainable levels, deployments require additional scrutiny. When the budget is healthy, ship with confidence.
This isn’t about slowing down—it’s about knowing when speed is safe and when caution is warranted. Error budgets transform reliability from a subjective judgment call into an objective, data-driven decision.
Real-Time Reasoning
During incidents, time is lost in understanding the issue rather than fixing it. With intelligence, the system answers instantly:
“Latency increased due to retry storms caused by downstream slowdown. Similar to the 3 prior incidents. Deployment is not a factor.”
This approach reduces MTTR by 40–60% in environments with complex service dependencies and mature data pipelines.
Blast Radius Visibility
Before any change, understand its potential impact. The Intelligence Layer maps not just direct dependencies, but transitive ones—the services that depend on services that depend on you.
“This deployment affects the payment service, which has 23 transitive dependents across 4 teams and processes 15% of daily transactions.”
Armed with this context, teams make informed risk decisions. High blast radius during peak hours? Maybe wait. Low blast radius on a non-critical path? Ship confidently. The goal isn’t to block changes—it’s to ensure every change is made with full awareness of its potential impact.
Safer Deployments
Most outages actually happen when you’re rolling out new code. The Intelligence Layer acts like a safety net—it checks things like traffic patterns, how services usually behave, which dependencies might be fragile, and what’s happened in the past. If something looks risky, it gives you a heads-up or even stops the rollout before anything breaks.
Incident Learning Loop
Most systems detect incidents. Few learn from them.
After every incident, the Intelligence Layer automatically correlates what changed, which signals appeared first, and how the issue propagated. These patterns feed back into detection—updating baselines, adding correlation rules, and refining predictions.
The same failure mode never surprises you twice. A memory leak pattern discovered during one incident becomes a detection rule for all similar services. A cascading failure path identified in post-mortem becomes a monitored dependency chain. Each incident makes the system smarter, compounding reliability improvements over time.
Noisy-Neighbor Detection
Kubernetes is really good at making sure resources are used efficiently, but it doesn’t always keep noisy neighbors apart. The Intelligence Layer can pick up on which services are struggling when they’re sharing space, and brings these hidden problems to light—making it possible to fix issues that would be almost impossible to spot on your own.
How an Intelligence Layer Works
The Intelligence Layer sits above Kubernetes, not inside it. It doesn’t replace Kubernetes—it augments it by enabling perception, understanding, prediction, reasoning, and action.
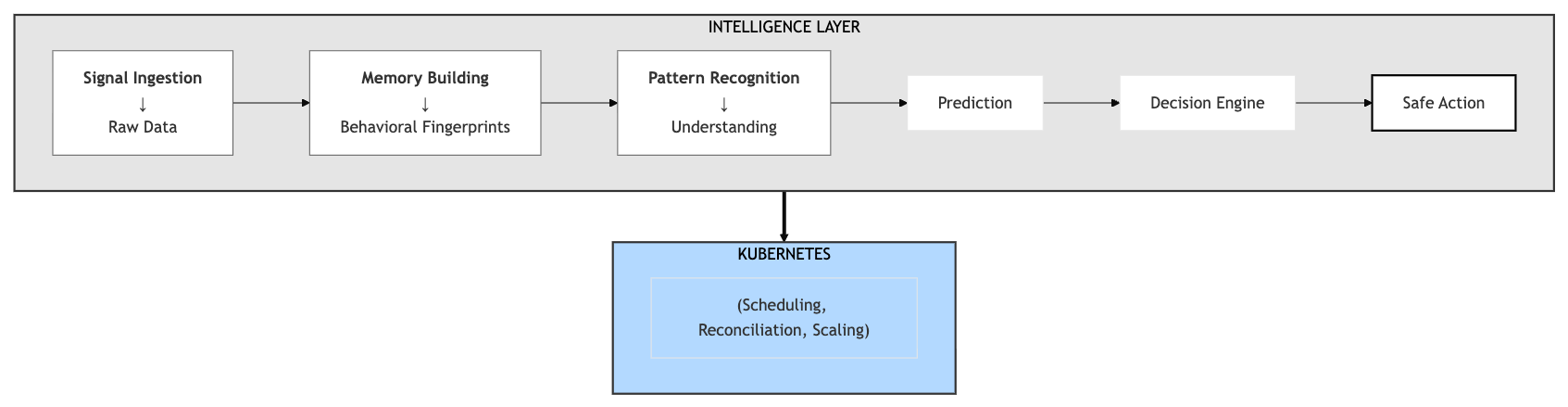
Signal Ingestion: It takes in everything: metrics, logs, traces, Kubernetes events, deployment history, node signals, and even how everything is connected. But instead of just building more dashboards, the real goal here is to actually understand what all that data means.
Building Memory: At first, all those metrics might just look like noise. But over time, the system starts to spot patterns and build up a real sense of how each service behaves—tracking things like its usual response times, relationships with other services, and what’s happened during past incidents. This paints a unique behavioral fingerprint for every microservice.
Pattern Recognition: This is basically the brain of the system—the place where raw data turns into real understanding. It figures out what normal looks like, spots when things start to get weird, recognizes the warning signs before failures, and notices if a deployment is acting out of character.
Prediction: It’s a complete shift—from always playing catch-up to finally getting ahead of problems. So rather than just sending a generic “CPU crossed 90%, alert!” message, the system can warn you early: “Hey, CPU usage is climbing too fast for the autoscaler to keep up—at this rate, you’ll probably hit your limits in about 12 minutes.”
Decision Engine: It takes everything into account—risk levels, past behavior, and which dependencies might be sensitive—to determine the smartest move. That might mean scaling up early or pausing a deployment.
Safe Actioning: Intelligence becomes autonomous action with guardrails: confidence scores, fallback mechanisms, human-in-loop options, and audit logs ensure automation never becomes dangerous.
Why This Matters Now
This intelligence layer wasn’t feasible five years ago. Three breakthroughs changed that:
Observability Maturity: Thanks to OpenTelemetry becoming the new standard, we’re finally getting consistent, high-quality telemetry across the stack. With 445% year-over-year growth, it’s now the second-highest velocity CNCF project. The fragmented world of observability tools is now coming together around a single set of standards.
Proven ML Models: The technology behind anomaly detection, time-series forecasting, and cause-and-effect understanding has finally grown up. These models used to live in research papers, but now they’re reliable enough for day-to-day operations. Tools like Google’s TimesFM and CMU’s MOMENT (both making waves at ICML 2024) are proof that these advanced models are no longer just experiments—they’re ready to handle real-world workloads.
Infrastructure Scale: At the scale we’re dealing with today, the payoff finally outweighs the hassle. Handling 10 microservices by hand? Totally doable. But try wrangling 500 by yourself—suddenly, it’s a different story. That’s why most Fortune 500 companies are now running hundreds of microservices, often spread out over several clouds.
Stricter SLO Requirements: People expect more these days. A bit of downtime that would have been fine five years ago just isn’t tolerated anymore. Companies are feeling the squeeze to bounce back faster from problems, hit stricter uptime goals, and keep their cloud bills in check.
The technology is ready. The need is urgent. The question is no longer “Can we build this?” but “How quickly can we adopt it?”A Note on Limitations
Intelligence layers are not magic. They require:
- Learning periods (typically 7+ days) to establish accurate baselines
- Clean telemetry to make accurate predictions
- Human oversight for high-stakes decisions
- Graceful degradation when ML components fail
The goal is augmentation, not replacement. The best systems know when to defer to human judgment.
The Path Forward
Kubernetes provides a powerful foundation for running containers, but today’s systems demand more than just orchestration. They demand understanding.
An Intelligence Layer learns how every service behaves, predicts failures before users feel them, reasons through incidents, and makes smarter, safer decisions. It doesn’t replace Kubernetes—it completes it.
The future of platform engineering is not just more automation—it’s intelligent automation.Related Posts
The Physics of Scale: Mathematical Foundations for Intelligent Infrastructure
Before building intelligent systems, we need to understand the physics that governs them. Two laws change how you think about scalability forever.
From Sidecars to Kernel: Building an Observability Stack for the Intelligence Era
Shifting telemetry collection from user-space proxies into the kernel isn't just a performance win. It changes what you can actually see—and how much you pay for that visibility.